
Lex Podcast Speaker Prediction with OpenAI Whisper
An exploration of re-purposing OpenAI’s Whisper model to perform speaker prediction on Lex Fridman podcasts.
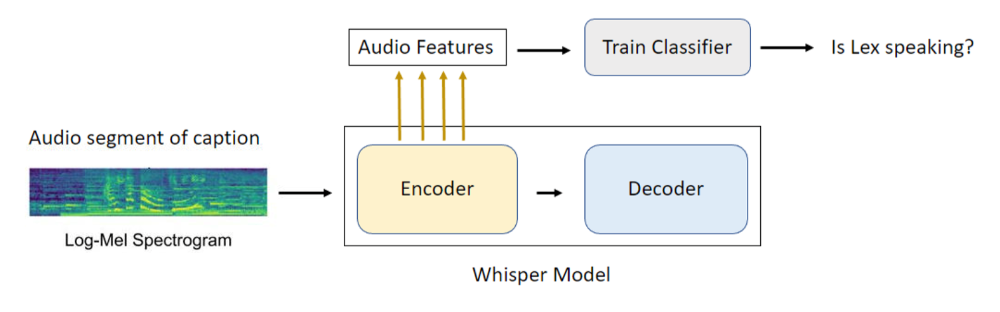
To enrich Lex Fridman podcast captions with speaker tags, I investigate if the hidden states of Whisper can be used as zero-shot audio features to train a classifier to predict if lex is speaking or not. There’s also a code walkthrough of the experiments, from creating the audio features by extracting the different hidden encoder states of Whisper to training a classifier.
Accompanying code:
This work is motivated by Andrej Karpathy’s Lexicap project, which he shares in this twitter thread. He transcribed Lex Fridman podcasts using OpenAI Whisper.
TL;DR
Experiments revealed that despite Whisper’s design to capture speaker-invariant features for speech-to-text tasks, its hidden states can be repurposed for speaker identification. By using these hidden states as zero-shot audio features, a classifier can effectively predict whether Lex is speaking, with the 14th out of 24 encoder layers in the medium.en model proving the most effective, achieving a 93% F1 score. This suggests that Whisper’s encoder captures speaker-specific patterns and provides representative features for speaker identification. However, being a speech-to-text model, it’s also possible that the model performs well because its hidden states have implicitly captured common words used by Lex and not just speaker-specific acoustic features.
OpenAI Whisper
Whisper is a transformer-based model trained to perform multilingual speech recognition. Apart from speech recognition, it was also trained to perform speech translation and language identification. The key question here is if this robust model can be used to generate zero-shot audio features suitable for a classifier to perform speaker prediction.
Approach
Whisper hidden states
Despite the task of speech recognition (speech to text, the original objective) and speaker prediction (classifying which speaker is speaking, our objective) being different, the approach I explore is based on leveraging the encoder hidden states. The initial idea is guided by the idea of transfer learning.
For example, transfer learning in vision models enables utilizing a model trained on one vision task, on a different one, while using much fewer data samples. The transfer learning for vision is based on the idea that the early layers of the model learn key low-level visual features which can be very useful and shared across different tasks. And that the later layers of the model learn the more high-level task-specific features. Hence during fine-tuning in vision, the early layers can be frozen from a different model, and the later layers are trained on the new task. The similar idea of pre-training and finetuning applies to transformers as well.
Transformer encoder in Whisper has 24 encoder blocks (medium.en). I explore utilizing the outputs of some of these encoder blocks to train a classifier for speaker prediction.
Project Walkthrough
The project can be divided into 3 parts:
- Dataset Creation:
- Creating a labelled dataset of audio segments and corresponding caption pairs, where we assign a binary label to each pair (Whether Lex Fridman is talking or not)
- Audio Feature Extraction:
- Extract the required audio features from the audio segment using Whisper
- Speaker prediction model:
- Train a classifier on these audio features to predict if Lex is speaking
Dataset Creation
The dataset used for training can be found here. This CSV file captures an audio segment, its caption (from Whisper large), and its corresponding label.
This was a manually created dataset, where an audio segment and its caption were labelled 1 or 0. The Whisper-processed captions were obtained from Karpathy’s website present in this repo.
In addition to manually labelling the data points, I also heuristically labelled data points based on patterns from the podcast. For example, if “the following is a conversion” is a caption that occurs in the first few minutes of the podcast, we know it is Lex speaking. Similarly, if there are ads about “Cash app”, I assign the speaker to Lex.
Extraction of Zero-Shot Audio Features
To extract audio features, the required hidden states of the encoder must be captured. I do this with a few line changes by logging the outputs of various encoder blocks, which is done in this fork. These encoder hidden states can be accessed easily after a forward pass.
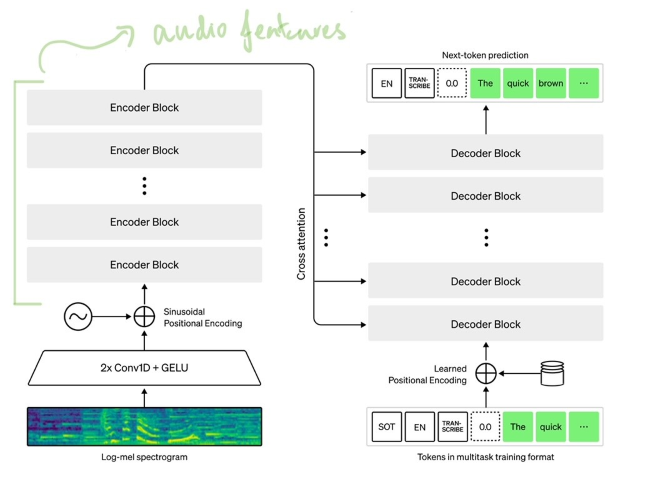
Figure: Whisper Model Architecture
Another aspect of utilizing the hidden state is feature engineering. The encoder captures the hidden states at 1500-time windows (number of mel spectrograms) in each audio segment. The shape of the encoder block output is (bs, 1500, hidden_size). We need to reduce this 1500 into 1 dimension to train a classifier. To summarize these features, I utilize the mean and standard deviation across all time windows and create the feature of shape (bs, hidden_size+ hidden_size).
Training a Classifier for Speaker Prediction
After creating the audio features, a SVM is trained to perform speaker prediction on audio segments. This jupyter notebook contains a walkthrough of training a classifier for speaker prediction.
Evaluation
The model was evaluated on different train-test splits and the results were averaged. To better simulate the testing scenario, train-test split was performed based on unique podcasts rather than on random audio segments. Thus, podcasts and guests seen in the test set were unseen in the training set. Note: one or two guest speakers might be present in training and testing if the same guest features in more than one podcast.
Findings
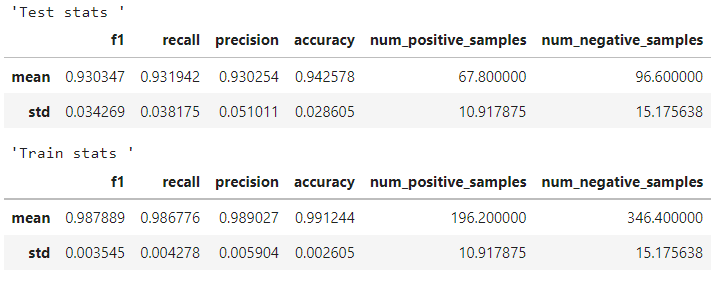
The output of the middle encoder block (block 14 out of 24) of OpenAI whisper (medium.en) produces reasonably rich features for speaker prediction on this dataset. It results in a F1 score of 93%. Using this hidden state is better in comparison to using the 1st, 2nd, and the last. Using the output of the 1st and 2nd encoder blocks result in poor performance (80% F1 score) with heavy overfitting. These metrics can be found in the training notebook. Using the last encoder output also works but performs slightly worse than using the middle block. Interestingly, when using the small.en model instead, the 2nd encoder block produces the more optimal audio features for this task compared to using the middle and last.
To summarize the metrics, a F1-score of 93% and an error rate of 5.8% was achieved on the speaker prediction task using the output of the middle encoder block of Whisper. However, there is overfitting (train F1-score of 98.8%, error rate of 0.9%) and the standard deviation of the precision and recall across train-test splits is higher than expected (~4%). This could be mitigated with more training data.
I had expected the earlier layers of the encoder blocks to give better performance because of the difference between the original objective and the task at hand. The task of the speech-to-text encoder in Whisper might be to create audio features independent of the speaker (more based on the occurrences and words) but the task at hand is speaker prediction (more dependent on the speaker than occurrence). A similar point about the effect of this task difference was made here. Despite this, the audio features are reasonably rich for speaker prediction and using the earlier hidden states help.
Conclusion and Future Work
In spite of the reasonable performance of using zero-shot audio features from Whisper, the performance can be more robust given the F1 score and the level of overfitting. These are some approaches based on Whisper that are worth experimenting with to improve the performance on this task:
- More labelled data
- Better summarization of time windows of hidden state
- Explore using operations other than mean and standard deviation to summarize the time windows.
- Richer embeddings via finetuning of whisper encoder
Ending Note
There clearly might be more optimal methods to perform speaker prediction other than using the heavy Whisper model. This blog post is an exploration of how to utilize Whisper’s hidden states for a different task and how useful this can be.
Feel free to share your thoughts or feedback.