
Differentiable Faithful Question Answering
A deep dive into a differentiable knowledge base architecture for faithful question-answering
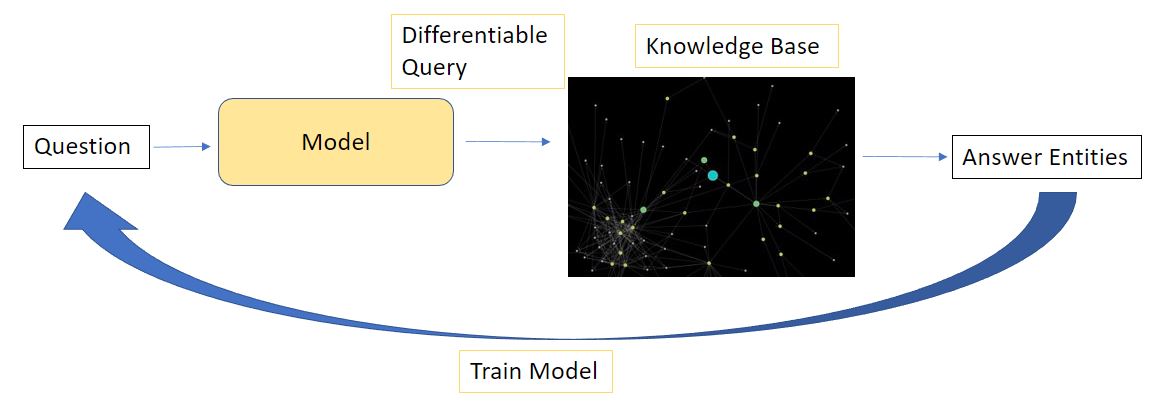
To enable question-answering, knowledge bases are commonly made differentiable through knowledge graph embeddings but they are not faithful to the knowledge base. A faithful question-answering system ensures that the answers it generates are consistent with the underlying knowledge base and faithfully represent the information contained within it. This work [1] proposes an architecture of a differentiable knowledge base, called Reified KB, which enables a language model to faithfully query a knowledge base for answers.
This work has applications in enabling factual question and answering systems such as Alexa and Siri. For example, factual questions such as “How tall is Barack Obama” or “Who starred in Forest Gump”, require access to factual information.
This typically involves a querying system (eg. LMs, Semantic Parsers+Query Generation) to interact with a factual database to retrieve answers. For knowledge graph-based approaches, this factual information is typically stored in knowledge bases as triplets. Let’s introduce the format of this knowledge base. If you already know these fundamentals, skip the below section.
Knowledge Bases
Knowledge bases are databases of triplets containing factual information in the form of triplets. Triplets contain 3 items, a subject (also called the head), an object (also called the tail) and the relation (label of how the subject is related to the object). The items in the subjects and objects are called entities. These are examples of triplets:
- Barack Obama (head/subject) -> Born in (relation) -> United States (object/tail)
- Tom Hanks (head) -> starred in (relation) -> Forest Gump (object)
Here, Barack Obama, United States, Tom Hanks, and Forest Gump are entities. These entities can have relations with other entities. For example, Tom Hanks can have relations with Actor, Forest Gump, Sully, California, 183m.
This database can also be represented in the form of a graph – a knowledge graph. This is a directed graph where each node (subject) is connected (with a directed edge) to another node (object). The figure below shows a subgraph of a knowledge graph:
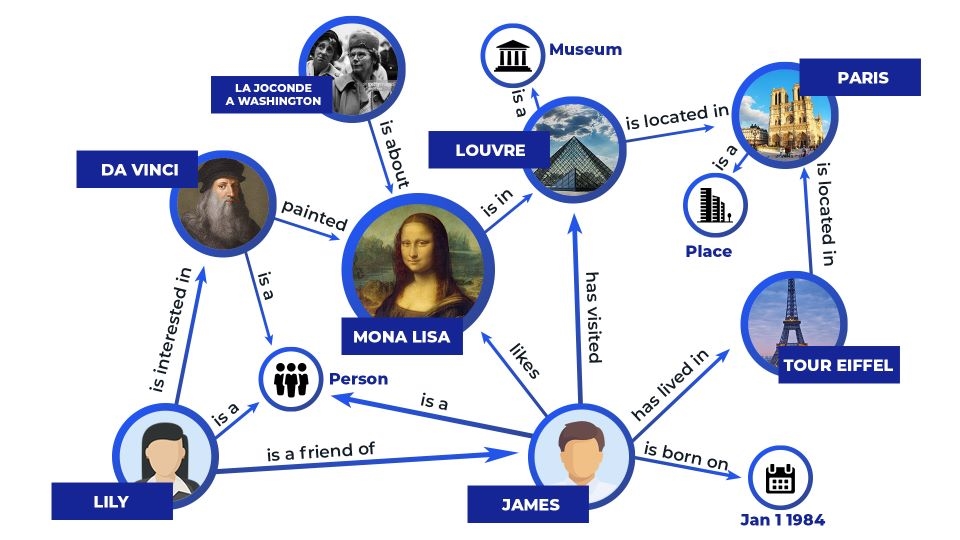
Image Source: https://thetechbrook.com/inside-the-black-box-of-ai/
Querying this knowledge base
Most fundamentally, this knowledge base can be queried if we know the subject and relation we want to access. This would translate to just a WHERE clause in an SQL query. There are a few challenges here when dealing with question answering. One, given a question we need to capture the subject and relation. Two is that to arrive at an answer, we may need to traverse more than 1 relation. For example, in the above figure, if we need to answer the question of where is the Mono Lisa located, we need to first traverse to Louvre and then to Paris. The third challenge is missing relations altogether, such as if there was no edge between Louvre and Paris. In this case, we’d have to perform some kind of deductive reasoning to arrive that the answer.
Approaches to query KB for QA
Arriving at the core topic of discussion. How can we query this knowledge base in a differentiable manner? A differentiable query is useful because it will allow for end-to-end model optimization of the question modelling and answer retrieval.
One popular method in which this is done is through learning knowledge graph embeddings (feature vectors for entities and relations) and answering a question by performing operations on these embeddings. These works include approaches such as query-to-box [2] and some others [3] , [4]. One shortcoming of Query2Box has do with the question modelling- it requires heuristic rules to generate the query plan (the dependency graph) from the question.
Other methods that do not require training of graph embeddings are approaches based on heuristic parsers [5], [6]. These utilize natural language parsers to generate structured queries which are executed on KBs. There are also approaches based on neural methods that generate these structured queries [7]. However, this data related to structured queries and questions are hard to acquire [1],[8]
In contrast to the approach above with neural/heuristic parsers, approaches on the lines of the Reified KB [1] require just the raw question, the head entity, and the answer for training. Along with the KB. This doesn’t require the data related to a structured query. Let’s now dive deeper into this work
Reified KBs- Differentiable Operations on a KB
This work [1] defines a differentiable approach to query a KB. And utilizing this operation they train a neural network in an end-to-end fashion (query included) to answer questions over a knowledge base. The authors defined a format to store the knowledge base termed a “reified KB”. And an operation is designed to perform a differentiable query on this KB, through a “follow” operation. Given a subject entity and a relation, this operation will follow the path of the relation to arriving at the objects.
How is this knowledge base differentiable? Good intuition for this can be got from how the embedding layer (word embedding layer in word2vec for example) is differentiable- by emulating a lookup with a matrix multiplication between one-hot encoded vector and an embedding matrix.
Breaking down the “follow” operation
The Reified KB is created by breaking down the knowledge base into 3 matrices: The subject matrix Msubj (T x E), relation matrix Mrel (T x R), and object matrix Mobj (T x E). Here T, R, E are the number of triplets, relations, and entities in the knowledge base, respectively. Each row in Msubj, is the headID (one hot encoded, hence of size E) of the triplet Tn . Similarly, each row in Mrel (one hot encoded relation id) is the relation of triplet Tn. Each row in Mobj is the objectID (one-hot encoded) in triplet Tn. The subject matrix, relation matrix, and object matrix are represented using a sparse matrix format. If not for a sparse matrix this would require unfeasible amounts of memory.
Given a headID and a relationID, how do we transverse to the objectID? This is done according to the following equation:
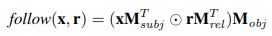
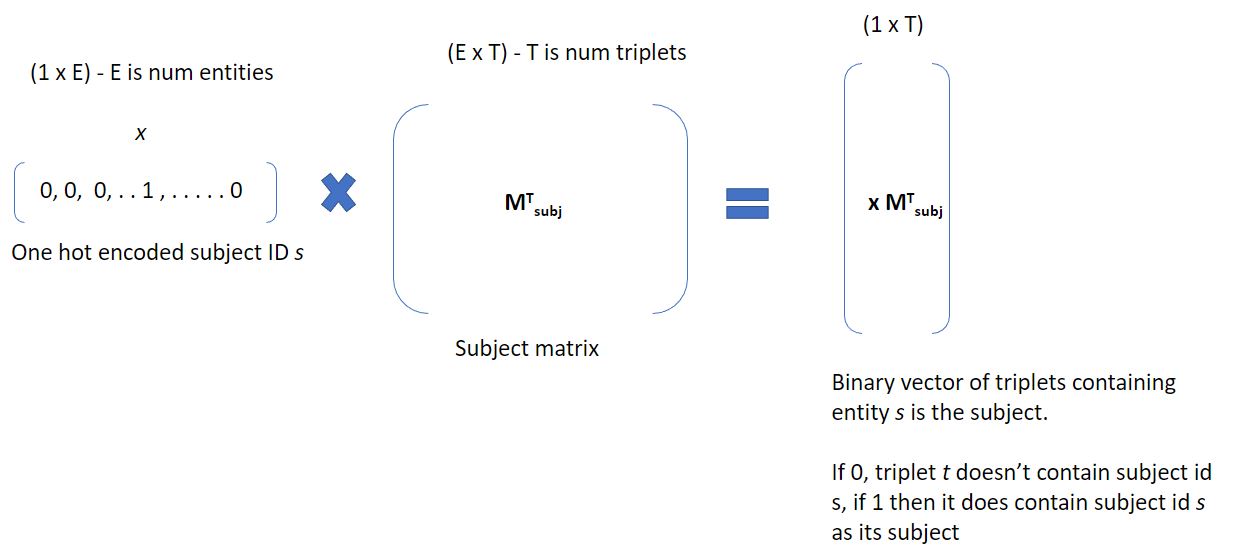
We first utilize the subject vector x, which is one hot encoded. Matrix multiplication is performed between the subject vector x (1 x E) and the subject matrix (E x T) to obtain a vector (1 x E). This operation essentially queries those triplets that have subject in x in their subject. Entries with 1’s are triplets containing subject x and 0’s are triplets that don’t. For x, the size is (1 x E) for purpose on this discussion. It actually will be of size (batch_size x E). This operation is summarized below:
We do the same for the relation. We perform matrix multiplication between relation vector r (1 x R) with the relation matrix (T x R). This essentially queries those triplets containing relation r (T x 1). Then we perform element-wise multiplication between xM__subj and rM__ rel which leads to the selection of those triplets that have the same subjectID and relationID.
Now that we have queried those triplets that have the same subjectID and relationIDs, we want to “follow” the subject of concern using this relation to obtain the object (answer). To do this, we multiply this resulting (1 x T) vector with the object matrix (T x E) to object the vector that contains all the answer object ids (1 x E). The indices of those elements with value 1 are the answer object ids.
The code for the “follow” operation can be found here
This is just a summary of a key method proposed in the paper. Refer to the paper for more details surrounding this- such as the literature review, complexity analysis, memory optimizations, and implementation variations.
The Implementation
The custom implementation can be found here. This implements the key aspects of the reified KB and the model training, but it’s not an exact replication- this implementation utilizes a transformer-based question encoder, as opposed to word2vec.
Single Hop
Here, we utilize the transformer to encode the question similar to this: For 1 hop questions, we predict the relation using a linear layer, given the latent question representation. We obtain a probability distribution of relations by utilizing a Softmax activation function. This is now the relation vector that we utilize to perform the following operation outlined above. After the “follow” operation is performed, we obtain the object ids that belong to the answer. The objective function used is binary cross-entropy, similar to this work. This entire pipeline is summarized in the figure below:
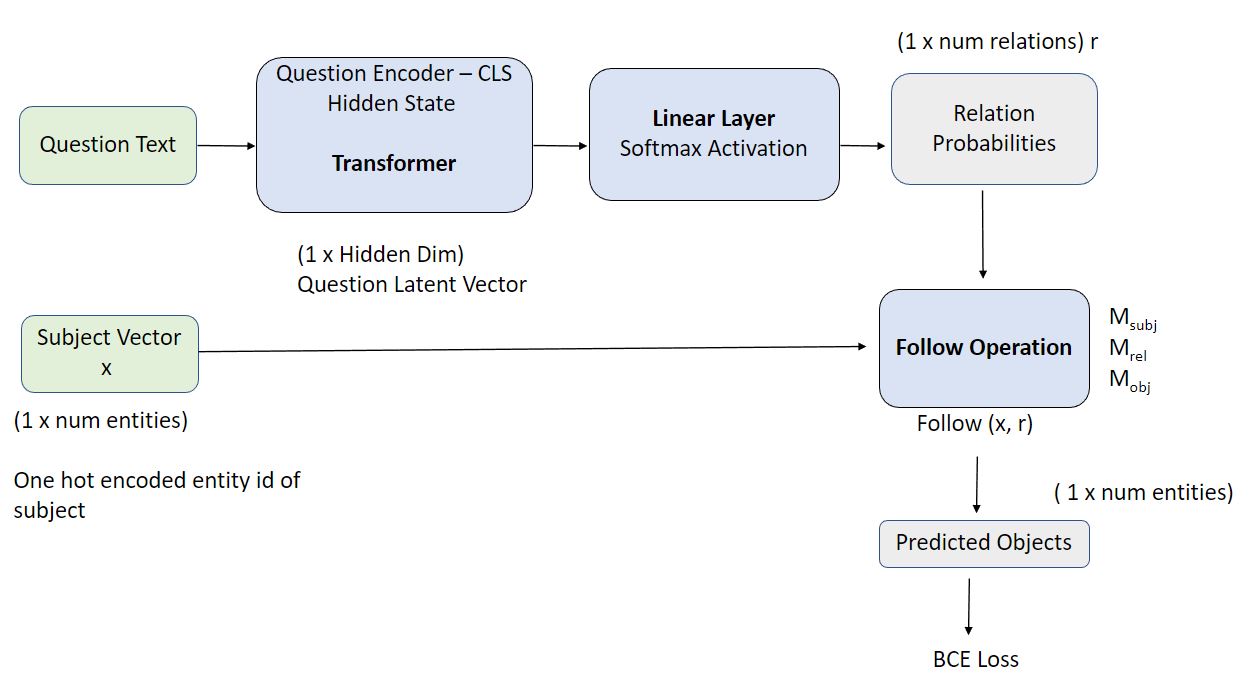
When testing this model, there was a key observation that limits its practical use as it is. When tested on unanswerable questions, this model provided outputs by predicting “starred in” relationships- Code. To enable this model’s use in a practical setting, we would also somehow have to handle unanswerable questions.
Multi-Hop
The multi-hop case, with hop H, is very similar to the single hop case, except that we perform the “follow” operation H times. Given the question encoded vector, we predict the relation vector and perform the “follow” operation on subject S to arrive at object O. We then predict another relation vector using a different linear layer. We then follow the new subject O, according to this second relation vector to arrive at the new object O2.
Metrics
The training scripts and metrics are in the repo. The metrics on the MetaQA benchmark is summarized below:
| MetaQA | Hit @k =1 |
|---|---|
| 1-hop | 0.977 |
| 2-hop | 0.787 |
| 3-hop | 0.821 |
Codebase
This implementation: Repo
Google’s Offical implementation: Repo
Interesting Following Work
There has been interesting following work based on this Reified KB paper. I’ve summarized some of the salient points below:
- Work 1: Expanding End-to-End Question Answering on Differentiable Knowledge Graphs with Intersection
- Utilizes a transformer question encoder instead of word2vec
- Implements attention to perform model multi-hop relations
- Handles multi-entity questions by utilizing an intersection operation
- Work 2: End-to-End Entity Resolution and Question Answering Using Differentiable Knowledge Graphs
- Addresses the real-world application aspect of utilizing the reified KB approach – in that we do not have access to the ground truth subject entities at inference
- The work addresses this by performing entity extraction and entity linking to retrieve the subject entity, encode the question, and then query the KB. This training is done end-to-end
Feedback
Please feel free to reach out to me for feedback, corrections etc