
Attribute Vector Steering in Stable Diffusion: A Hands-On Guide
Controllable image generation with CASteer, from using simple hooks to experiments to improve generation stability.
What if you could dial an image generation between photorealistic and anime style with a slider? Prompt engineering with strength-related keywords is one approach, but can be imprecise. CASteer addresses this by guiding the model’s hidden states internally, in the continuous domain, giving finer control (Gaintseva et al., 2025).
This post presents a hands-on exploration of attribute steering in Stable Diffusion using CASteer (Gaintseva et al., 2025), detailing both implementation steps and experiments. This will go through the underlying implementation details so one can tweak and experiment with the method on their own. It demonstrates how to construct and apply steering vectors, compose multiple attributes, and investigates approaches to improve generation stability and efficiency.
Accompanying code:
Introduction
CASteer is an approach that can help guide diffusion models to generate images with certain styles or attributes (Gaintseva et al., 2025). For example, if you want to generate an image and add an anime theme to it, one approach is to simply prompt the model. However, with prompting, it’s harder to have fine-grained control over the strength of the theme. Moreover, in image generation applications, users often want to adjust attribute strength continuously— choosing higher values to produce stronger versions of the attribute.
CASteer achieves this not through prompt engineering, but by adding/substracting a learned “style” or “attribute” vector into the hidden states during generation, guiding the model toward the desired attribute. Because we manipulate the hidden states, the strength of the effect can be adjusted arbitrarily. Using this, for example, one could smoothly interpolate between “anime” and “photorealistic” with a slider to find the right balance. We’ll walk through exactly how CASteer can be implemented.
1 Method
Cross-attention steering (CA-Steer) modifies the hidden states inside diffusion models to apply semantic attributes (e.g., metallic, anime). To guide a model’s generation toward or away from a target attribute, we will construct steering vectors. The process involves four steps:
1.1 Prompt dataset creation
We start by defining two sets of prompts: positive prompts that contain the target attribute and a baseline prompt without it. Using these pairs of prompts, we collect activation data from the diffusion model.
Attribute: "Cinematic shot of a horse, metallic-chrome sculpture, 4K detail"
Baseline: "Cinematic shot of a horse, 4K detail"
Dataset size is usually 50 pairs of positive and negative prompts showcasing the same attribute.
1.2 Cache Cross Attention Outputs
Given a dataset of pairs of prompts, we want to cache activations related to the positive prompt and negative prompt. For each pair of prompts, we cache one vector derived from the cross attention output. The figure below shows the architecture of the SD 1.5 Generation Pipeline, with annotations indicating how vector steering is integrated into the process.
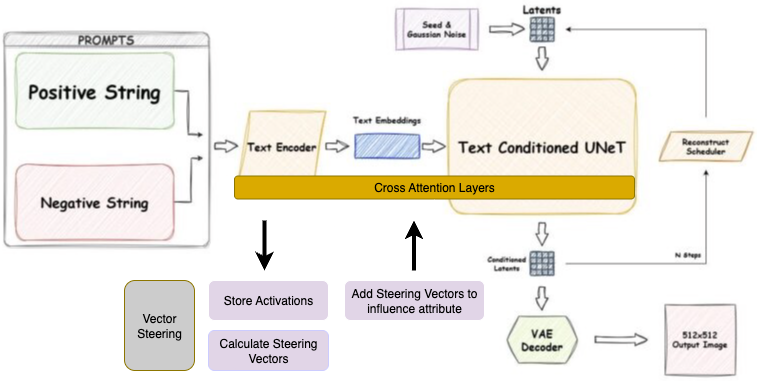
Figure: Architecture of integrating vector steering into the diffusion pipeline (SD 1.5 pipeline from Demir’s blog).
The cross attention output is of shape (2, L, dim) for SDXL, representing (unconditional/conditional axis, sequence length, dim). For vector steering, we take the conditional axis (index 1) and average across L to get a vector for the positive attribute.
Implementation-wise, we can use hooks to record inputs/outputs of any layer. So first, we find cross attention layers using:
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0")
targets = []
for name, m in pipe.unet.named_modules():
if getattr(m, "is_cross_attention", False):
targets.append((name, m))
Then, create a hook that just records cross attention outputs implemented here. Below is a simplified version:
class SteeringHooks:
"""
Registers on cross-attn blocks. Either:
(A) Records activations into .cache
(B) Applies provided steering vectors
"""
def __init__(self, args):
self.cache = []
self.steer_vectors = []
self.step = 0 # current diffusion step
def hook_fn(self, module, inputs, x_seq):
"""
Parameters:
- module: The torch module (e.g., a linear or attention layer) where the hook is registered.
- inputs: The input tensors passed into this module during the forward pass.
- x_seq: The output tensor from this module. In cache mode, we record x_seq for later analysis and return it unchanged. When applying steering, we modify x_seq by adding the steering vector and return the adjusted output.
"""
self.step += 1
if self.in_cache_collection_mode: # collect activations
self.cache.append(x_seq[1, :, :].mean(0).detach().cpu()[None, None, :])
return x_seq # return output unchanged
if self.applying_steering_vectors:
# Bias cross attention output with steering vector
return self.steer_vectors[self.step] + x_seq
The official implementation is super useful as well, but takes a different approach to collecting activations - they do it by rewriting the cross attention logic and integrating it in, as shown here
1.3 Calculate Steering Vector
The idea here is to capture the “essence” of an attribute by seeing how it changes the model’s hidden states compared to a neutral baseline. If we know what adding “anime” (vs. not adding it) does to the activations, the difference gives us a direction we can later push the model along.
Formally, the steering vector is defined as the difference between the average hidden activations of the positive and baseline prompts:
\[v = \frac{1}{N} \sum_{i=1}^N h(x_i^{+}) - \frac{1}{M} \sum_{j=1}^M h(x_j^{-})\]where (h(x)) is the activation of prompt (x) at the chosen layer, (x_i^{+}) are positive prompts, and (x_j^{-}) are baseline prompts. This difference isolates the attribute by cancelling out shared factors, leaving a vector (v) that points in the direction of “more attribute” in activation space.
At the end of this process, we obtain steering vectors for each cross-attention layer, shaped as (num diffusion, dim).
1.4 Applying Steering Vectors
Now that we have a vector capturing the “direction” of the attribute, the idea is to guide the model during generation by nudging its hidden states along that direction. Pushing in the positive direction strengthens the attribute, while pushing in the negative direction suppresses it.
During inference, the hook can be configured to inject the appropriate steering vector at each diffusion timestep. At each forward pass, we adjust the cross-attention activations by adding or subtracting a scaled version of (v):
\[h'(x) = h(x) + \alpha v\]In practice, we perform a renormalization to ensure we affect only the direction of the vector and not its magnitude, as shown here.
2 Results:
2.1 Hyper Parameters:
- Model: SDXL (
stabilityai/stable-diffusion-xl-base-1.0) - Number of prompt pairs: 20 (prompts)
- Number of diffusion steps: 20
- Guidance scale: 5
- Seed: 1
- Alpha: Sweep of steering strengths
2.2 Metallic and Anime Steering

Figure 1: Castle with metallic steering vector, prompt: “Epic fantasy castle on top of a mountain, clouds swirling around, dramatic lighting.”

Figure 2: Batman close-up using anime steering vector, prompt: “Cinematic close-up of Batman’s face, dramatic shadows across the cowl, ultra-detailed, 4K.”
While increasing the steering strength can enhance the desired attribute, it often affects the overall image structure as well. For example, in the dog generation below, higher steering weights not only intensify the anime style but also alter the dog’s posture. These results can be reproduced with this notebook.

Figure 3: Dog in anime style, prompt: “Close-up of a labrador sitting.”
2.3 Composing Attributes
Until now, we’ve explored steering single attributes. To guide models with multiple attributes at once, you can form a composite steering vector by taking a weighted average of the individual attribute vectors.
merge_alpha = 0.5 # weight for the first steering vector
for i in range(len(steering_vector1)): # iterate over all steering vectors
merged = merge_alpha * steering_vector1[i] + (1 - merge_alpha) * steering_vector2[i]
merged = F.normalize(merged, p=2, dim=-1)
steering_vector1[i] = merged
This method can combine not only concrete features (like anime style) but also more abstract qualities, such as happiness.
For example, to steer an image toward a happier expression, we used the calibration prompts as shown below:
Attribute: "Close-up of Mickey Mouse’s face, happy expression, cartoon style"
Baseline: "Close-up of Mickey Mouse’s face, neutral expression, cartoon style"
Below are two composite examples where anime style is blended with happiness:

Figure 4: Dog with composed anime and happiness steering vectors, prompt: “Close-up of a labrador sitting.”
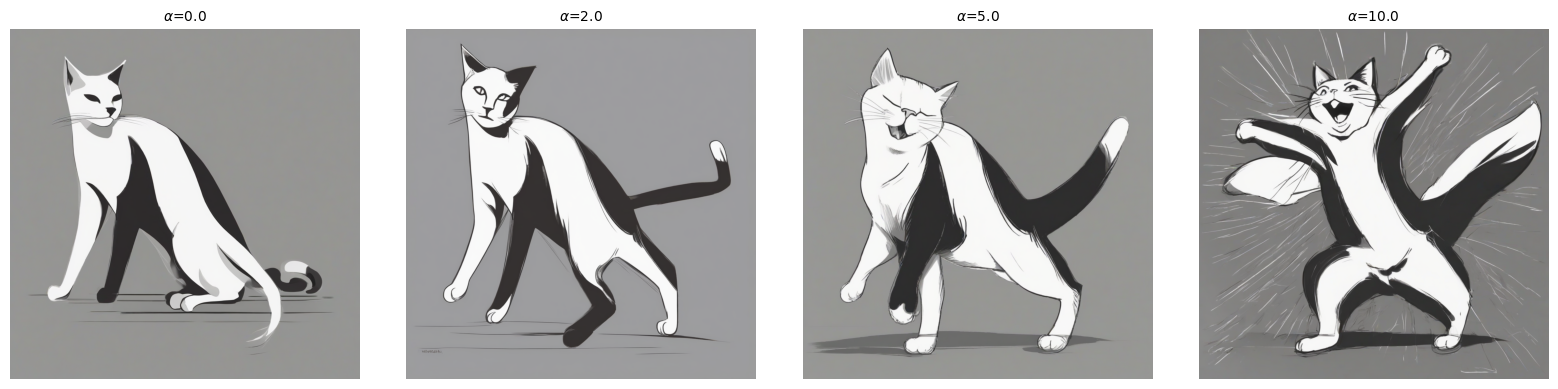
Figure 5: Cat with composed anime and happiness steering vectors, prompt: “Minimalist black-and-white sketch of a cat stretching.”
This approach allows flexible composition of multiple attributes by adjusting merge_alpha. These results can be reproduced with this notebook.
3 Experiments
3.1 Improving Stability
Via Diffusion Steps
I noticed that quite often the image structure changes, instead of just the attribute, when steering strength increases. This is evident in Figure 3 and possibly also in Figure 2.
In the diffusion process, Gaussian noise is gradually added until the data are nearly destroyed (Ho et al., 2020). This means that the reverse process necessarily reconstructs the global frame before fine-grained attributes. Therefore, early diffusion steps likely generate the structure.
Motivated by this, I experimented with withholding steering until the 3rd diffusion step, to better preserve the original structure. This approach may require adjusting the steering strength. As shown in Figures 2 and 3, delaying steering helps maintain the initial composition more effectively compared to Figures 6 and 7.

Figure 6: Dog using anime steering vector, steering only after first 2 diffusion steps, prompt: “Close-up of a labrador sitting.”

Figure 7: Batman close-up using anime steering vector, steering only after first 2 diffusion steps, prompt: “Cinematic close-up of Batman’s face, dramatic shadows across the cowl, ultra-detailed, 4K.”
Via Layer Selection
Apart from addressing stability by delaying the addition of steering vectors, another approach can be to apply steering vectors to only a fraction of the cross-attention layers. Ablation E in the CASteer paper demonstrates that this can be an effective way to target image attributes rather than overall image composition. In particular, they found that applying steering to the last 36 cross-attention layers of SDXL (“up” block layers) strikes a good balance of attribute influence and global image composition.
Feel free to experiment with this. It’ll only require doing an additional check before adding a steering vector hook: here
3.2 Improving Efficiency
In order to reduce diffusion latency, I explored whether we can leverage diffusion replay caching. In this, we can iterate on the image for the first N/2 diffusion steps and only then apply the steering vector. If this works, then for an adaptive use-case, where we need to run multiple versions of the image with different strengths, we can reuse the diffusion output of the N/2 step and then, as the strength changes, we only perform N/2 diffusion steps instead of N. This can improve diffusion latency by 50%, compared to running all N steps with the updated strength.
Experiments revealed that late-stage steering, even with higher strengths, resulted in the same outputs. It appears that without early intervention, such as from the third step in section 3.1, the steering vector’s influence is diminished, limiting its effectiveness in attribute styling.
4 Closing Insights
- Normalizing steering vectors is crucial to influence the attribute direction. Try experimenting with removing that and renormalization here and here.
- Increasing steering strength enhances attributes but may impact global composition.
- Applying steering vectors only after the initial two diffusion steps can help maintain the global image structure.
- Diffusion replay caching cannot be used to improve performance in adaptive use cases, since applying steering only after N/2 diffusion steps is too weak to meaningfully affect the output.
References
Gaintseva, T., Ma, C., Liu, Z., Benning, M., Slabaugh, G., Deng, J., & Elezi, I. (2025). CASteer: Steering diffusion models for controllable generation. arXiv. https://arxiv.org/abs/2503.09630
Demir, E. (2023, August 2). The arrival of SDXL 1.0: Introducing SDXL 1.0: Understanding the diffusion models. Towards Data Science. https://towardsdatascience.com/the-arrival-of-sdxl-1-0-4e739d5cc6c7
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. arXiv. https://arxiv.org/abs/2006.11239
Feedback
Please feel free to reach out to me for feedback, corrections, etc.